
It ain’t no Combine, but …
let seq1 = AsyncSequence.From([1, 2, 3, 4, 5])
let seq2 = AsyncSequence.From([6, 7, 8, 9, 10])
let currentValue = AsyncStreams.CurrentValue<String>("a")
Task {
try await AsyncSequences
.Merge(seq1, seq2)
.prepend(0)
.handleEvents(onElement: { print("new integer element \($0)") })
.withLatestFrom(currentValue)
.scan("") { accumulator, value in return "\(accumulator) (\(value.0) \(value.1))" }
.collect { print("new element is collected \($0)") }
}
currentValue.send("b")
currentValue.send(termination: .finished)
At a first glance we could think it is 100% Combine code: Merge, prepend, handleEvents, scan and even CurrentValue. Those are things we are used to seeing in a reactive programming world.
However this is no Combine. This is 100% structured concurrency using AsyncSequence but with a little help from AsyncExtensions. AsyncExtensions not only brings “Combine like” operators to AsyncSequence, it also provides helpers like Just, Timer or Zip and equivalents to Subject with Passthrough, CurrentValue or Replay.
Before exploring some operators that AsyncExtensions can offer, let’s take a look at the fundamental nature of Combine and AsyncSequence with three simple diagrams.
Different and similar at the same time
Combine
Combine, implementing a reactive programming paradigm, is a push and pull system. In other words, it implements both the Observer and Iterator patterns. To better understand this, let’s take a look at this diagram:
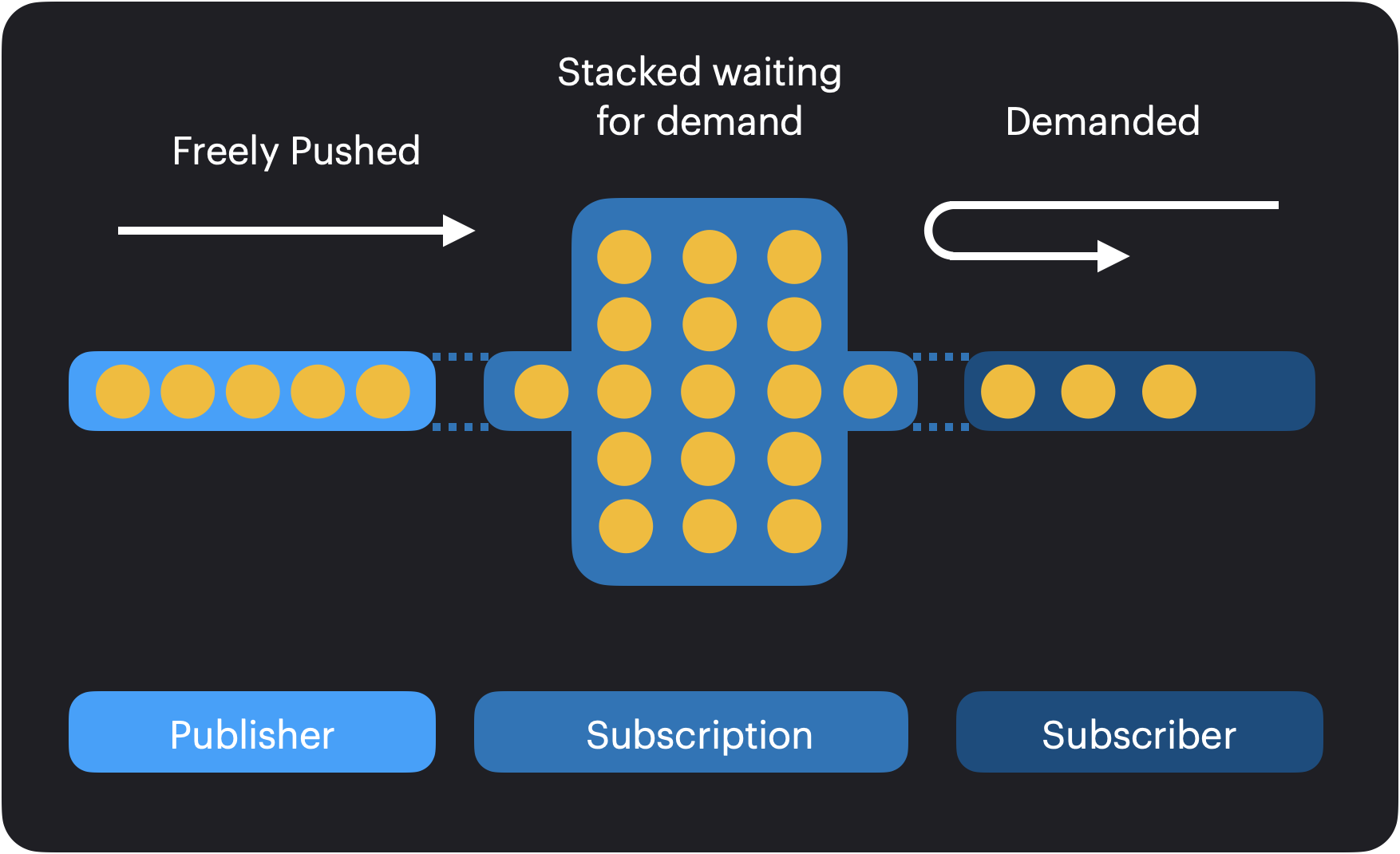
There are three actors involved in a Combine stream:
- the Publisher: produces values over time
- the Subscriber: demands an amount of values it can process
- the Subscription: regulates the flow of values from the publisher to the subscriber
Why do we need to regulate the flow of values? Because the subscriber might produce values faster than the subscriber can consume them. If we do not regulate the flow, then the subscriber might be overwhelmed by the amount of things to process and it could lead to an inconsistent state or even a crash. This mechanism is called back pressure management. It enforces that the publisher meets the demand of the subscriber, potentially using a queue to stack values.
The important take away here, is that a Combine stream is a push and pull system.
AsyncSequence
An AsyncSequence is simply an asynchronous version of the Sequence protocol. It is a pull system. In other word, it implements the Iterator pattern. To better understand this, let’s take a look at this diagram:
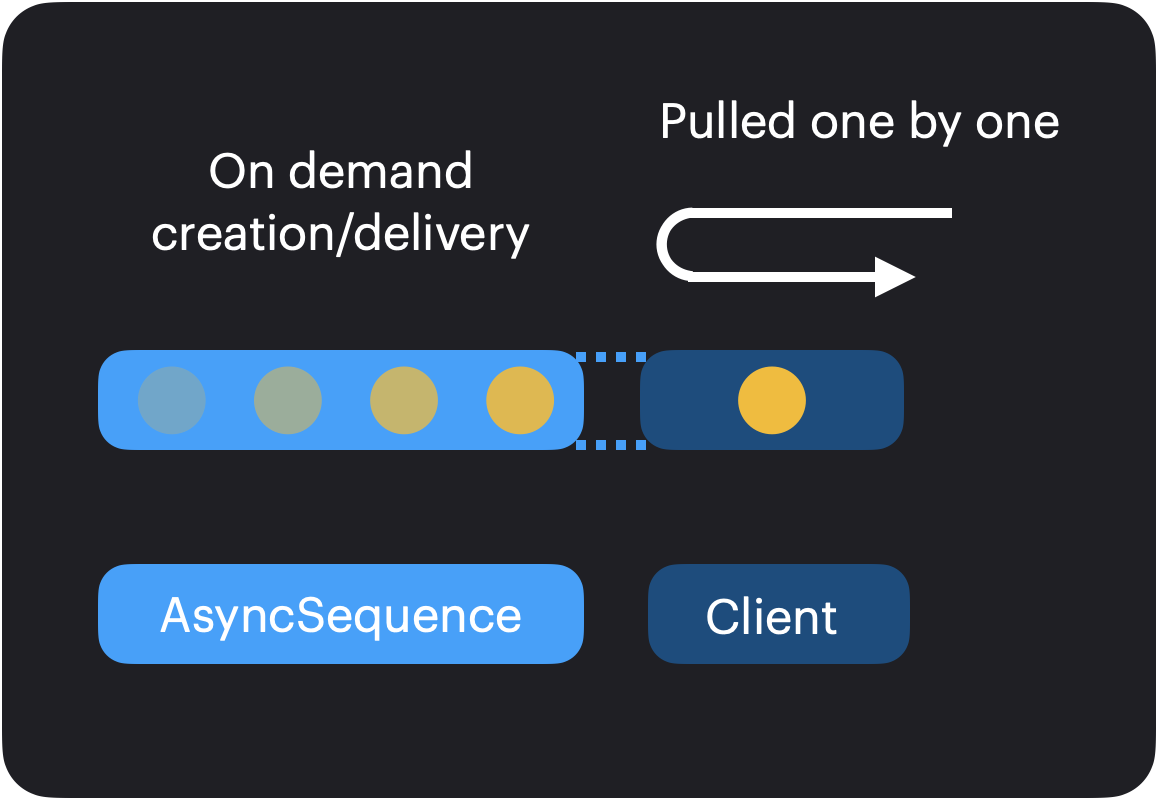
There are two actors involved in an AsyncSequence usage:
- the AsyncSequence: produces on-demand values over time
- the Client: demands values one by one
Since this is not a push mechanism, the AsyncSequence cannot produce values unless it is explicitly asked to. There is no need for a regulation system. An AsyncSequence, by design, respects the pace of its client.
The important take away here, is that an AsyncSequence is a pull-only system.
AsyncStream
There is a special flavor to AsyncSequence that does not entirely respect the aforementioned definition. AsyncStream is a type of AsyncSequence that is also a push system.
To better understand this, let’s take a look at this diagram:
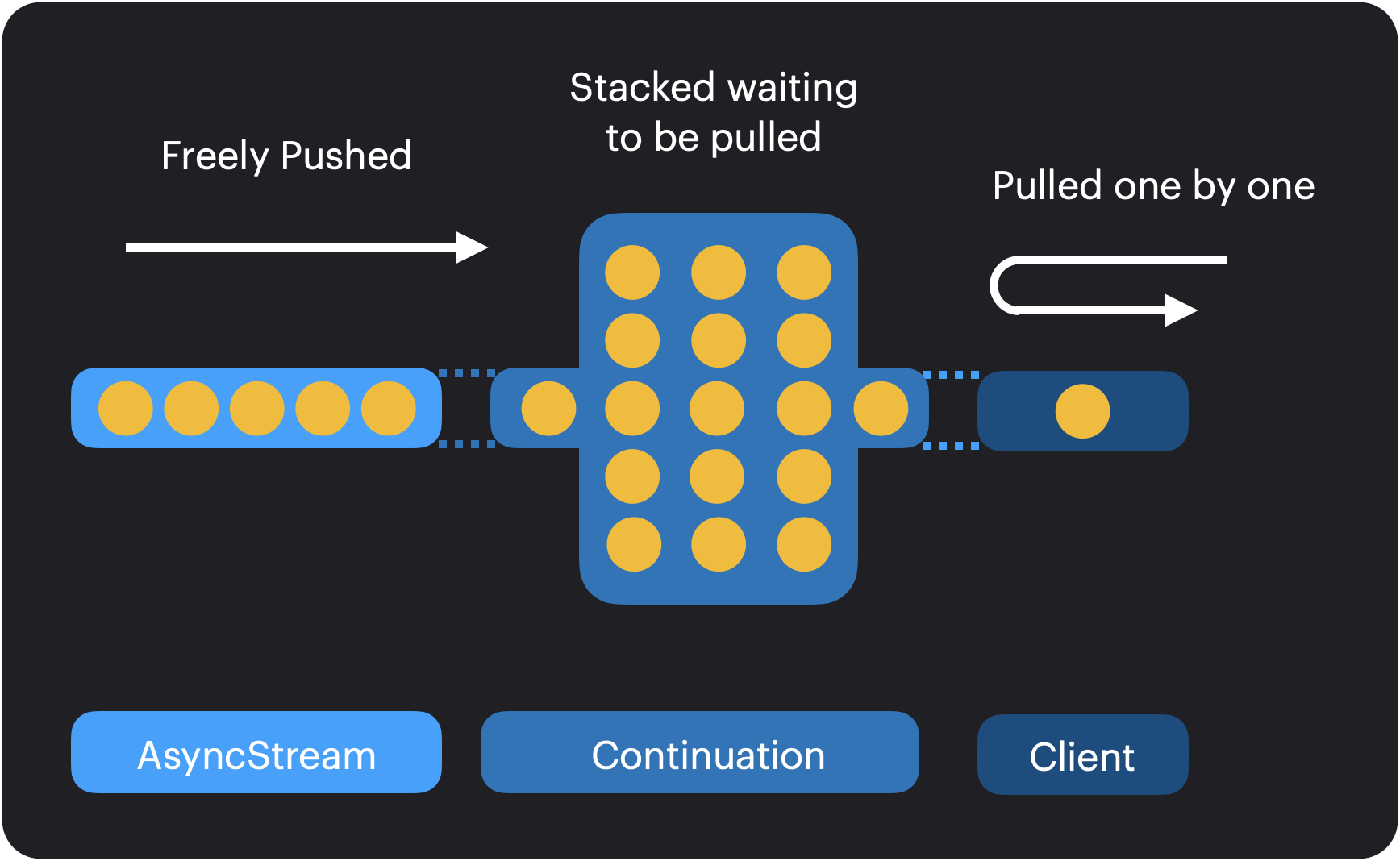
There are three actors involved in an AsyncStream usage:
- the AsyncStream: produces values over time
- the Client: demands values one by one
- the Continuation: acts as a middleware between the AsyncStream and the Client stacking values and waiting for the Client to pull them
For the same reason that a Combine stream needs a regulation system, so does an AsyncStream. Being a push and pull system, an AsyncStream needs an internal queue to stack values, waiting to be consumed by its client. The main difference with a Combine stream is that this is still a one by one pull system. The client sets the pace for values popping as if it was Combine stream with a constant demand of one.
The important take away here, is that an AsyncStream is a push and pull system, with a client demand maxed out to one.
A trivial example of Combine operator porting: scan
scan is very similar to reduce, the only difference is that it will emit every intermediate value between the initial value and the last one.
Although it is fairly simple, scan is not currently provided as an AsyncSequence operator.
Here is an example of its usage with Combine:
[1, 2, 3, 4, 5]
.publisher
.scan("") { accumulator, currentValue in
accumulator + "\(currentValue)"
}
.sink(receiveValue: { print($0) })
// will print:
1
12
123
1234
12345
From that observation, we can infer the bevaviour we want for the equivalent AsyncSequence: each value served by its iterator should be the result of the execution of a closure taking the previous computed value and the next value from the source AsyncSequence.
Here is the AsyncIterator implementing such a behaviour:
struct AsyncScanIterator<SourceAsyncIterator: AsyncIteratorProtocol, Output>: AsyncIteratorProtocol {
typealias Element = Output
var sourceIterator: SourceAsyncIterator
var currentValue: Element
let nextPartialResult: (Element, SourceAsyncIterator.Element) async -> Element
public init(
sourceIterator: SourceAsyncIterator,
initialResult: Element,
nextPartialResult: @escaping (Element, SourceAsyncIterator.Element) async -> Element
) {
self.sourceIterator = sourceIterator
self.currentValue = initialResult
self.nextPartialResult = nextPartialResult
}
public mutating func next() async rethrows -> Element? {
guard !Task.isCancelled else { return nil }
guard let nextSourceValue = try await self.sourceIterator.next() else { return nil }
self.currentValue = await self.nextPartialResult(self.currentValue, nextSourceValue)
return self.currentValue
}
}
Here is the code for the AsyncScanSequence that uses that iterator:
func scan<Output>(
_ initialResult: Output,
_ nextPartialResult: @escaping (Output, Element) async -> Output
) -> AsyncScanSequence<Self, Output> {
AsyncScanSequence(self, initialResult: initialResult, nextPartialResult: nextPartialResult)
}
struct AsyncScanSequence<UpstreamAsyncSequence: AsyncSequence, Output>: AsyncSequence {
typealias Element = Output
typealias AsyncIterator = AsyncScanIterator<UpstreamAsyncSequence.AsyncIterator, Output>
var upstreamAsyncSequence: UpstreamAsyncSequence
var initialResult: Output
let nextPartialResult: (Output, UpstreamAsyncSequence.Element) async -> Output
init(
_ upstreamAsyncSequence: UpstreamAsyncSequence,
initialResult: Output,
nextPartialResult: @escaping (Output, UpstreamAsyncSequence.Element) async -> Output
) {
self.upstreamAsyncSequence = upstreamAsyncSequence
self.initialResult = initialResult
self.nextPartialResult = nextPartialResult
}
func makeAsyncIterator() -> AsyncIterator {
AsyncScanIterator(
upstreamIterator: self.upstreamAsyncSequence.makeAsyncIterator(),
initialResult: self.initialResult,
nextPartialResult: self.nextPartialResult
)
}
}
Here is an example of its usage:
[1, 2, 3, 4, 5]
.asyncElements // computed property provided by AsyncExtensions that transforms a sequence in its async counterpart
.scan("") { accumulator, currentValue in
accumulator + "\(currentValue)"
}
.collect { print($0) } // a function provided by AsyncExtensions that iterates over an async sequence in a functional style
// will print:
1
12
123
1234
12345
There is no particular difficulty in implementing such an operator. A pull system is well suited for that kind of linear output, one value at a time, at the client’s pace.
Not that trivial when chronology matters: Timer
Let’s try to re-implement an AsyncSequence version of Combine Timer.publish(every:on:in:). I can see two ways of doing so: one involves a traditional AsyncSequence, the other involves an AsyncStream.
For the sake of this demonstration, we will limit the Timer to a 1 second interval.
AsyncSequence
struct AsyncTimerSequence: AsyncSequence {
typealias AsyncIterator = Iterator
typealias Element = Date
func makeAsyncIterator() -> AsyncIterator {
Iterator()
}
struct Iterator: AsyncIteratorProtocol {
func next() async throws -> Element? {
guard !Task.isCancelled else { return nil }
try await Task.sleep(nanoseconds: 1_000_000_000)
return Date()
}
}
}
AsyncStream
struct AsyncTimerStream: AsyncSequence {
typealias AsyncIterator = Iterator
typealias Element = Date
func makeAsyncIterator() -> AsyncIterator {
let timerStream = AsyncStream<Date>(Date.self, bufferingPolicy: .unbounded, { continuation in
Task {
while !Task.isCancelled {
try await Task.sleep(nanoseconds: 1_000_000_000)
continuation.yield(Date())
}
}
continuation.finish()
})
return timerStream.makeAsyncIterator()
}
}
Let’s see how it behaves
With AsyncTimerSequence:
let asyncTimerSequence = AsyncTimerSequence()
for try await element in asyncTimerSequence {
print(element)
}
// will print:
// 2022-03-15 20:00:24 +0000
// 2022-03-15 20:00:25 +0000
// 2022-03-15 20:00:26 +0000
With AsyncTimerStream:
let asyncTimerStream = AsyncTimerStream()
for try await element in asyncTimerStream {
print(element)
}
// will print:
// 2022-03-15 20:00:24 +0000
// 2022-03-15 20:00:25 +0000
// 2022-03-15 20:00:26 +0000
So far both implementations behave the same, printing dates with a 1s interval. As we saw, an AsyncSequence is a pull system only: the client imposes its pace. What happens if the client performs a long operation between each iteration?
Let’s simulate that with a Task.sleep(nanoseconds: 2_000_000_000).
With AsyncTimerSequence:
let asyncTimerSequence = AsyncTimerSequence()
for try await element in asyncTimerSequence {
try await Task.sleep(nanoseconds: 2_000_000_000)
print(element)
}
// will print:
// 2022-03-15 20:04:24 +0000
// 2022-03-15 20:04:27 +0000
// 2022-03-15 20:04:30 +0000
Dates are printed every 3s, and their values have indeed a 3s interval (1s for the Timer + 2s for each iteration).
With AsyncTimerStream:
let asyncTimerStream = AsyncTimerStream()
for try await element in asyncTimerStream {
try await Task.sleep(nanoseconds: 2_000_000_000)
print(element)
}
// will print:
// 2022-03-15 20:04:24 +0000
// 2022-03-15 20:04:25 +0000
// 2022-03-15 20:04:26 +0000
Dates are printed every 2s BUT their values have a 1s interval.
This is because AsyncStream is a both a push and pull system. Each date is pushed every 1s in the continuation, independently from their consumption (which happens every 2s).
I’m not saying there is a best way to implement a Timer, but it is important to be aware of the different strategies. Of course we can mitigate this by decoupling the dates consumption from their creation by wrapping the long operation inside a Task.
for try await element in asyncTimerSequence {
Task {
try await Task.sleep(nanoseconds: 2_000_000_000)
print(element)
}
}
// or
for try await element in asyncTimerStream {
Task {
try await Task.sleep(nanoseconds: 2_000_000_000)
print(element)
}
}
With that in place both Timers behave the same.
What about concurrent clients?
Concurrent clients mean iterating over the same AsyncSequence from several concurrent loops. We can give it a try with a trivial example: an AsyncSequence that provides every 1s an auto-incremented counter to clients.
struct AsyncCounterSequence: AsyncSequence {
typealias AsyncIterator = Iterator
typealias Element = Int
func makeAsyncIterator() -> AsyncIterator {
Iterator()
}
struct Iterator: AsyncIteratorProtocol {
var counter = 0
mutating func next() async throws -> Element? {
guard !Task.isCancelled else { return nil }
try await Task.sleep(nanoseconds: 1_000_000_000)
self.counter += 1
return counter
}
}
}
let asyncCounterSequence = AsyncCounterSequence()
Task {
for try await counter in asyncCounterSequence {
print("Task1, counter = \(counter)")
}
}
Task {
for try await counter in asyncCounterSequence {
print("Task2, counter = \(counter)")
}
}
// will print:
// Task2, counter = 1
// Task1, counter = 1
// Task1, counter = 2
// Task2, counter = 2
// Task1, counter = 3
// Task2, counter = 3
As expected, each client has its own independant version of the counter. Under the hood, the for … in loop calls the makeAsyncIterator() function and two different Iterators are produced, each one having its own counter state.
Just for fun, what would happen if we wanted to share the same iterator in a concurrent context? First we have to make it a reference type so that it is not copied when accessing it from two different Tasks.
class Iterator: AsyncIteratorProtocol {
var counter = 0
func next() async throws -> Element? { // removing mutating since this is a class
guard !Task.isCancelled else { return nil }
try await Task.sleep(nanoseconds: 1_000_000_000)
self.counter += 1
return counter
}
}
Then we have to use a while loop on the same iterator:
let asyncCounterSequence = AsyncCounterSequence()
let iterator = asyncCounterSequence.makeAsyncIterator()
Task {
while let counter = try await iterator.next() {
print("Task1, counter = \(counter)")
}
}
Task {
while let counter = try await iterator.next() {
print("Task2, counter = \(counter)")
}
}
// will print:
// Task2, counter = 2
// Task1, counter = 1
// Task1, counter = 4
// Task2, counter = 3
// Task2, counter = 6
// Task1, counter = 5
As you can see, the result in non-deterministic since the next() function is called concurrently. Some calls will be done by the first Task and some by the second.
In this dummy usecase it might not be an issue, BUT what if an AsyncSequence should really be shared with its results being exactly the same for every client?
A perfect example would be an AsyncSequence performing API calls while concurrent clients would process the results in different ways.
The following AsyncFetchUsersPagesSequence fetches pages of [User] against a fake Rest API on each call to next():
struct AsyncFetchUsersPagesSequence: AsyncSequence {
typealias AsyncIterator = Iterator
typealias Element = [User]
func makeAsyncIterator() -> AsyncIterator {
Iterator()
}
struct Iterator: AsyncIteratorProtocol {
var page = 1
mutating func next() async throws -> Element? {
guard !Task.isCancelled else { return nil }
guard self.page <= 9 else { return nil }
let request = URLRequest(url: URL(string: "https://www.server.com/api/users?page=\(self.page)")!)
let (data, _) = try await URLSession.shared.data(for: request) // no HTTP status code or error check for the sake of simplicity
self.page += 1
return try JSONDecoder().decode([User].self, from: data)
}
}
}
Let’s take the hypothetical case where we want to concurrently perform two distinct operations on the results, like logging them to the filesystem and persisting them to a database.
let usersPagesSequence = AsyncFetchUsersPagesSequence()
Task {
for try await users in usersPagesSequence {
try await log(users)
}
}
Task {
for try await users in usersPagesSequence {
try await persist(users)
}
}
By naively iterating on the sequence like that, we will double the calls to the API (just like with the Counter example). Not great performance wise.
On the other hand, if we share the AsyncIterator thanks to a reference type, we will end up having a non-deterministic behavior where some pages are logged and some are persisted. Not great for … well … not great!
In the Combine world, we can use a multicast() operator to mitigate that kind of issue. This operator ensures the upstream Publisher is executed only once while using a Subject to distribute the same results to every Subscribers.
AsyncExtensions provides such an operator. For it to work well, I had to develop some form of regulation preventing concurrent access to a shared AsyncSequence using Actor. You can find the details of the regulation mechanism here.
With that in place, we can use the AsyncFetchUsersPagesSequence without worrying about duplicate calls or non deterministic behavior.
let passthrough = AsyncStreams.Passthrough<[User]>()
let multicastedUsersPagesSequence = AsyncFetchUsersPagesSequence()
.multicast(passthrough)
Task {
for try await users in multicastedUsersPagesSequence {
try await log(users)
}
}
Task {
for try await users in multicastedUsersPagesSequence {
try await persist(users)
}
}
multicastedUsersPagesSequence.connect() // will unlock the client iterations
API calls will be performed once, while logging and persisting will happen concurrently on the same consecutive results.
Conclusion
AsyncSequence is easy to approach due to its simple protocol requirements. When combined with AsyncStream, it is definitely a possible replacement for Combine in certain situations. Let’s just not forget about its pull nature and its limitations when it comes to concurrency. AsyncExtensions aims to ease the usage of structured concurrency in most cases so we don’t have to switch between Combine and AsyncSequence. Some custom operators might have various possible implementations and I tried to respect the pull system whenever it was possible. Comments and pull requests are of course welcome so we can challenge those implementations.
I hope you enjoyed reading. Stay tuned.
A special thanks to Ryan F. for the nice review.